🚚 물류 유통량 예측 경진대회_1 [베이스라인 모델, EDA]
Baseline Model
- LGBM 사용
- ['물품_카테고리'] 라벨 인코딩
- Measure Metric: RMSE
# 라이브러리 임포트
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error
# 데이터 로드
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
# Categorical Feature Encoding
encoder = LabelEncoder()
encoder.fit(train['물품_카테고리'])
train['물품_카테고리'] = encoder.transform(train['물품_카테고리'])
test['물품_카테고리'] = encoder.transform(test['물품_카테고리'])
# Data set
train_X = train.drop('운송장_건수',axis = 1)
train_Y = train['운송장_건수']
#모델 정의
model = LGBMRegressor()
# Train-Test Split
X_train, X_test, y_train, y_test = train_test_split(
train_X, train_Y, test_size=0.3, random_state=42)
###Train: 22178, Test: 9506
# Model fitting & Prediction
model.fit(X_train, y_train)
pred = model.predict(X_test)
# Model Measurement
mean_squared_error(y_test, pred, squared=False)
- Baseline Code RMSE 입니다.
- 기존 제출 팀 점수를 보면 8.4인데, 5.84가 나왔기 때문에 overfit 가능성이 매우 높으니 data leakage 막으면서 rmse를 올릴 수 있는 방법을 적용해야 합니다.
1. Features
격자공간고유번호?
- 특정 거리마다 좌표를 격자로 구분하여 부여한 지리적 정보
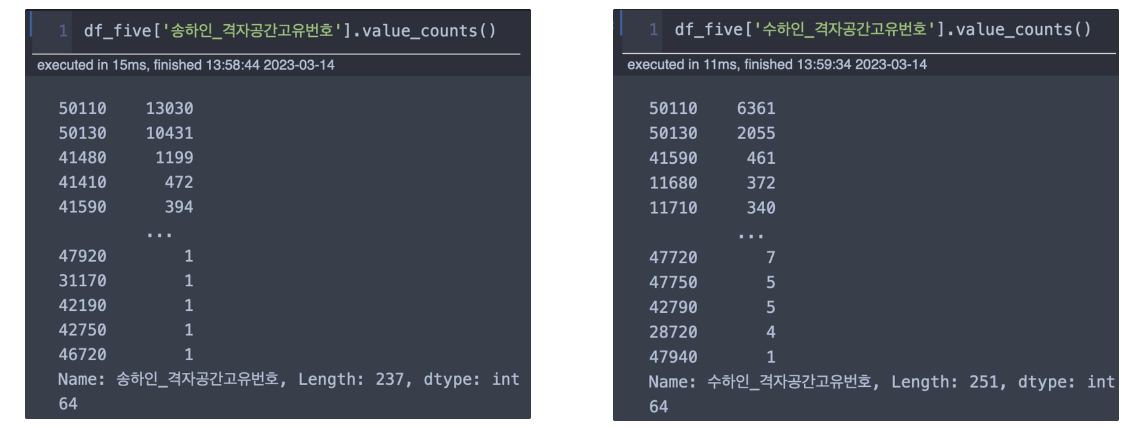
- 송하인, 수하인으로 나뉘어 하나의 인덱스 당 발송지, 수신지를 기록하고 있음을 알 수 있음
- Numeric 이지만 Categorical로 간주해서 생각해야 함
- 앞 5자리는 시/군/구를 나타냄
물품_카테고리?
- 해당 인덱스의 수하물 종류를 나타냄
- Categorical
운송장_건수?
- 해당 인덱스의 수하물 송장 개수를 나타냄
- 예측변수 → Numerical
2. EDA

송하인_격자공간고유번호
- 상위 5개 = 8775개 (27.69%)

수하인_격자공간고유번호
- 상위 5개 = 0.5%
- 송하인에 비해 수하인이 중복이 적다.
- 만약 앞 5자리 말고 나머지 숫자의 규칙성을 못 찾아내면 → 앞 다섯자리만 남기고 날리기
데이터 도메인에 대한 사전 지식이 없는 상태에서 바로 데이터를 봤습니다.
격자공간고유번호가 각 obs마다 부여되어 있는게 아니라 중복되어 있는 것을 확인했습니다.
그러나 송하인의 경우 상위 5개의 고유번호가 28%를 차지하고 있는 반면 수하인의 경우 0.5%로 송신과 수신 관계를 고려하면 타당한 비율이라고 생각이 듭니다. 뭔가 송신의 중점이 되는 물류센터들이 있을 것이고 수신은 각 개인들의 지점으로 보내는 것일테니까요.
2.1. 일단 앞 5자리 숫자만 남김
뭔가 앞자리 숫자들은 중복이 되는 거 같아 잘라보기로 했습니다.
송하인_격자공간고유번호
- 상위 5개 = 80.56%
하인_격자공간고유번호
- 상위 5개 = 30.26%
격자공간고유번호를 그대로 놔뒀을 때보다 앞 다섯자리만 남겼을 때 훨씬 유의미한 변수로 활용가능할 것
2.2. 앞 다섯자리 숫자만 남긴(df_five)에서 count기준 상위 5가지만 남김

25526개 (19.43%lost)
2.3. 상위 5개만 남은 데이터(df_only_five)에서 ‘물품_카테고리’ count 기준 상위 5가지만 남김

25526 →22710 (직전 대비11.03% lost) (원 데이터 대비 28.32% lost)
상위 5가지 종류만 남겼을 때 손실이 별로 크지 않습니다.
2.4. ‘송하인_격자고유번호’에 ‘물품_카테고리’ group by ‘index’
2.6. ‘송하인_격자공간고유번호’에 ‘물품_카테고리’ group by ‘운송장_건수’
- 송하인_격자고유번호: 5종류 int64 → 인데 사실상 object
- 물품_카테고리: 5종류 object
- 운송장_건수: int64 → target
- 송하인_격자고유번호를 일단 바꾼다 ?
- 송하인_격자고유번호가 50110일 때, 물품_카테고리 종류별 개수, 운송장_건수를 group by
- 그냥 노가다 해야 하나? →일단 group by로 살펴보기

2.5. ‘물품_카테고리’에 ‘송하인_격자고유번호’ group by ‘index’
2.7. ‘물품_카테고리’에 ‘송하인_격자공간고유번호’ group by ‘운송장_건수’

*주의: index는 ‘운송장_건수’가 아님. 즉, 해당 컬럼별 샘플의 개수
⇒ 특정 송하인과 물품_카테고리의 연관성이 있을 듯
운송장_건수 = ‘3’이 최저값
뭔가 격자공간고유번호와 물품 카테고리들이 관련이 있을 것으로 보입니다.
아마 제주도임을 고려하면 감귤 농장이 많은 지역이라던가 등으로 추론이 됩니다.

물품_카테고리
- 상위 5개 = 24152(76.22%)
- 격자공간고유번호보다 높은 중복률

Train Data 운송장 건수 평균 = 4.87


운송장 건수 최다 == 413
- 기타패션의류
- outlier 어떻게 처리할까?

운송장 건수 ≥ 30
→ 285개 (0.89%)

‘운송장_건수’가 30개 이상인 ‘물품_카테고리’
→ 농산물, 물류 등 원 데이터에서도 많은 수를 가지는 샘플들은 삭제해도 무방 but 비교적 작은 샘플들은 30개 이상짜리 함부로 날려도 괜찮을지?
물품 카테고리와 격자공간고유번호만 가지고 운송장 건수를 예측해야 하는 문제입니다.
더 쉽게 말하자면 어떤 종류의 물건을 어디서 어디로 보낼 때, 그 양이 얼마나 되는지 예측하는 것입니다.
실제로는 훨씬 더 다양한 변수들을 활용할 수 있겠지만 대회용 데이터기 때문에 변수들이 상당히 부족한 상황입니다.
또한 모든 변수가 categorical로서 사실은 수치 예측에 적합한 데이터는 아닙니다. 특히 high cardinality기 때문에 상대적으로 수가 적은 샘플들은 그 값이 정확하게 나오기 힘듭니다. 현실에서는 추가적으로 어떤 사람이 주문했는지, 시기는 언제인지 등등이 추가되어야 더 명확한 예측이 가능할 것으로 보입니다.
이어서 2편에 EDA 코드 및 성능을 올린 모델을 설명하도록 하겠습니다.